 Code inventories
Code inventories

Code inventories are lists of items iof the same type. It is also the process to making such list. The inventory is meant to provide a complete view over available ressources. Translated to code, PHP or else, it is an auditing process that collects code structures of one type, for further analysis.
For example, there is the inventory of regex, the inventory of string literals, the inventory of method names or the inventory of assigned and compared values. Each inventory collects a defined type of resources: they may be names, values or even a coding pattern. Then, those values are gathered, along with their localisation.
Initially, the localisation is not important. It becomes so after the analysis, so we can go back to the code and refactor it. So, it is usually collected from the beginning.
The most interesting part of inventories lies in the review of the scattered values : it is usually the first time they are together. Think about it : names of classes and namespaces are part of specifications or conception, so they are usually reviewed as a group. But regex or local variables fly below the radar, and are always created on the spot. They may take advantage of a group review.
Inventories do not yield bugs : they provide a different point of view on the code, and a broad one. Any observation in the inventory may become critical enough to become a bug, or, at least, the source of a bug.
Now, let’s see a few inventories, and how to extract from them interesting analysis, in growing order of complexity.
- Regex inventory
- Exceptions inventory
- Error message inventory
- Dynamic calls inventory
- Variables inventory
- String inventory
Regex inventory
Regex is one of the simple inventory available. They are strings, that are used with the preg* family of functions, in particular pregmatch() and pregmatchall(). Usually, regexes are a tool to filter and validate data. They are created as needed, unless they appear to be a classic pattern : then, they are usually looked up in a library of regexes.
/([a-z])([\d])//([A-Z]+)([A-Z][a-z])//([a-z\d])([A-Z])//([a-z0-9]{19,})/i/(\d{4})-(\d{2})-(\d{2}) (\d{2}):(\d{2}):(\d{2})//(\n+)(\s+)/smi/[\\\\^$.[\\]|()?*+{}\\-\\/]/~[^\w\s]~/[^0-9\.]//[^a-z_]/u/[^a-z-]//[^a-z0-9]/i/[^a-zA-Z0-9_\\-]//[^bkmgtpezy]/i/[A-Z]//\\.twig$/i#^/?([a-z0-9_-]+)/([0-9]+)$#i#^/?([a-z0-9_-]+)/([a-z0-9_-]+)$#i
It is easy to spot a few interesting situations :
- Several distinct delimiters
- Usage of unicode regex (
uoption) - Some of the regex are very close (difference in anchor, )
- Some regex could be replaced with PHP features (
.twigfile extension?)
All those observations now need more insights to be turned into an eventual refactorisation. Yet, this list is a good start to decide about refactorisation.
One feature that doesn’t appear is repetition. The regex presented here are not repeated, which could trigger a centralization process.
Exception inventory
The exception inventory plays a role akin to documentation. Indeed, it is hard to keep am updated list of available exceptions. So, exceptions are typically created on the fly, with an ad hoc name. That means there is little reusage.
The exception inventory helps with this. It acts as a documentation, merely by listing them all in one place. Sort them in alphabetical order, and you may easily detect that another existing exception already exists, and could be used again.
Secondly, the exception are even more easily read when documented within the PHP exception tree. We have an upgraded organisation of PHP exceptions since PHP 7.0, with Throwable at the top, Errors and Exceptions, and even several other categories, like RuntimeException, LogicException, etc.
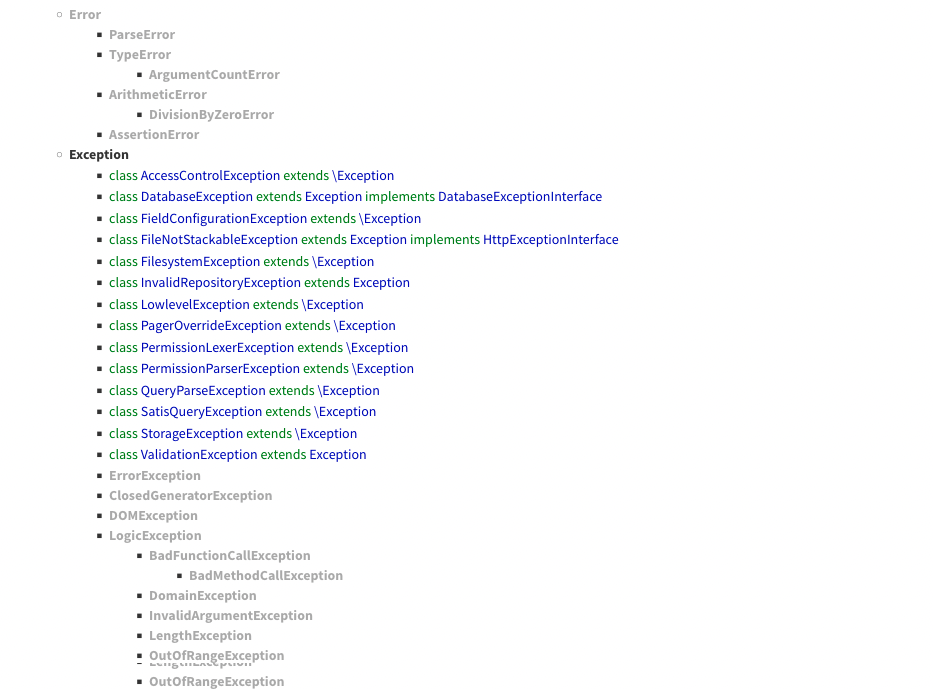
Dynamic codes inventory
Dynamic codes are expression build with variables. For example, $object->$method() or $closure(). Usually, those expressions are built with static names, which can be resolved at compile time. The dynamic calls rely on the the value of a variable, which may be coming from anywhere.
Dynamic code is usually rather tricky : it requires careful filter to avoid calling any arbitrary part of the code, and better organization to have random parts of the application called and returned.
The dynamic code inventory checks all the possible dynamic syntaxes. You can now check if they are necessary, of if they crept in the code without careful review.
Also, they are sometimes needed to extend other audits. For example, checking if a method is unused means reviewing all the explicit usage of that method, such as $object->method(), but also, checking the dynamic calls.
Error messages inventory
Error messages are strings, or may be concatenation. They are typically created on the spot, when one detect that an error may occur.
Error messages are a part of the string inventories. The latter is usually very simple, and also full of false positives. The error message inventory requires the message to be a string, and to be used with an exception, the trigger_error() native function, or the classic error reporting function of the framework.
Here is a selection of error message from an open source cms :
'Configuration template could not be loaded.''Could not find autoload.php, did you run "composer install" ..?''No endpoint given''The upload path ' . htmlspecialchars($upload_path) . ' either doesn\'t exist or isn\'t a directory.''We can\'t read data from ' . htmlspecialchars($upload_path) . ' - please check permissions and try again.''We couldn\'t automatically install the database schema: ' . $err[2]"$extension extension is not installed.""Could not write config file""Version file $versionfile could not be found, the code doesn't appear to be installed correctly.""You are not running an asynchronous message queue, so garbage collection is unnecessary."json_last_error_msg( )
Just as for the variables name, the review is interesting by itself. This time, it is for security reasons and maintenance reasons.
'No endpoint given'- Possibly not descriptive enough message
json_last_error_msg( )- Displays the last JSON error message
'We couldn't automatically install the database schema: ' . $err[2]- Displays the error from the database
"We couldn't find the schema doc."- Who is this
wein my code??
- Who is this
On the other hand, the rest of the messages look quite helpful : they might be handy in case of problem during execution.
Refactoring
Error messages inventory sets you in the same situation than the recipient of the message : without context. If those messages are not compelling or helpful now, they won’t be during an emergency. So, they are worth reviewing and updating.
The examples above didn’t show extreme situations, where the message is empty, or declare This is not possible, or include insults and sarcastic comments. However rare are the error, they should be removed.
Variables inventory
The variable inventory is straight forward : it collects the names of the variables in the code. This includes parameters, global and static variables, and local variables. Properties, static or not, and super-global variables are omitted.
Short variables
One simple review are the single letter variables. Those are usually considered too short to carry any semantic value, and should be avoided. Then, traditionally, some variables have classic names that everyone recognize : $i for loops, $e for caught exceptions, $k and $v for values in a foreach(), $r for a regex capturing sub-patterns, $x, $y and $z for coordinates in space…
Some specific one-letter variable may also be omitted because they are dedicated to a specific business logic.
Then, after removing the obvious one, the inventory may look like this : $a, $l, $b, $c, $o, $A, $B, $q, $d, $j, $_, $w, $h, $y, $g, $t, $f, $p, $s, $m, $n, $I.
Short variables, part 2
Besides the very short variables, there are also the slightly longer ones. Two letters variables are often a head scratcher, while 3 letters variable may show more meaning. Here is an inventory from a CMS, for 2 and 3 letters variables, along with their usage count. It is easy to decide when the variable makes sense or not.
$kk : 21 $fC : 24 $uc : 24 $fV : 26$tn : 26 $to : 26 $fd : 28 $LD : 29$ip : 32 $PA : 33 $rr : 33 $sF : 33$ss : 38 $ID : 43 $lP : 44 $el : 46$cp : 47 $cc : 58 $im : 81 $fN : 89$io : 246 $id : 940
The most interesting one is the twin variables $id and $ID. The only difference lies in the case. Is there a special meaning?
With 3 letters, the amount of meaningful variables goes up. The strange ones are now less numerous. See it for yourself.
$arr : 66 $cfg : 69 $reg : 71$len : 72 $new : 74 $rec : 77$col : 84 $var : 84 $tce : 88$foo : 97 $tca : 124 $dto : 130$ids : 137 $cmd : 156 $str : 174$res : 230 $tag : 262 $pid : 279$url : 371 $val : 397 $uri : 458$out : 600 $uid : 1079 $key : 2044$row : 2503
Confusing variables
Beside the size, there are a host of other confusing variable names. Here is a selection, with examples
- Names differing by one letter :
$has_recommended_replace_varsand$has_recommended_replacevars. - Names differing by case only :
$fullNameand$fullname - Partial inversion :
$basepathand$pathbase - Spelling mistakes :
$roowor$laake
Refactoring variables
After reviewing the variable inventory, you may end with a list of variables name that should be refactored. Here, ‘should’ depends entirely on who is reviewing the list. Inventory do not provide any suggestion of what is wrong or right : it is in the eye of the beholder.
The variable inventory is one of the semantics inventories. As it is now, and given that the code works, changing the names of those variables doesn’t change the code execution. And this is the case with any named structure in the code.
A semantic inventory aims at easing the readability of the code, by humans. Lengthening a variable names from $u to $user may improve the understanding of the code, and help maintenance in the long run.
This also applies to variables which are distant each other. Consider $basepathand $pathbase, that may be in two different and remote part of the code. As long as noone has to read those two methods at the same time, during a bug hunt, there is no harm. On the other hand, it may take a long time to realize that those two variables are actually distinct, because they look so much alike. Everyone has been there once.
String inventory
Honestly, this inventory is quite scary. Any large application has a huge list of them. Symfony has 746797 strings, with 247842 distinct. Cecil, a static website generator, has 2625, with 1004 distinct.
The obvious tip is to suggest to check all the double strings. In fact, check them as repeated, and start with the strings that are the most often repeated. When a string is repeated, turning it into a constant has good chances to make sense and help make the code more robust.
That is still a huge endeavor : first, finding those strings, and secondly, changing them into constants (global or class) in the code. Plus, the refactoring is never guaranteed. It is probably safe to replace contact@website.com by a global constant, but what about ‘Hello’ or ‘<H1>’. Those may not be easy to turning one or several distinct constants.
Pattern to group strings
With such a large inventory, we need to be smarter in order to detect strings with actual chances to refactorisation.
Instead of brute forcing the problem with usage statistics, we might consider how some of the strings are used. For example, consider literal which are used for state. The state is set in one part of the code, and then, it is tested in another part. This might be sumed up like this :
<?php
$object->state = 'alert';
// Lots of code, or even, different files
if ($object->state === 'alert') {
// doSomething()
}
?>
The ‘alert’ string is given to a property, and it is also checked later for the same exact value. Typical case for status. ‘alert’ acts as a status, an atomic amount of information, that is never changed. This means that the two different part of the code are actually linked, by that status’ value. We could improve the code by linking the two parts with a constant.
<?php
const STATUS_ALERT = 'alert';
$object->state = STATUS_ALERT;
// Lots of code, or even, different files
if ($object->state === STATUS_ALERT) {
// doSomething()
}
?>
Now, the challenge is in finding such strings in the inventory. You may notice that the same string is used in two different context : one is a full write, and the other a full comparison. The strings are always used as a whole, not as a part of something else. With that, we can build a pattern to spot those strings.
We are looking for strings that : + are used several times (at least twice) + is only using =, == and === (with some variations) + is at least once written to a variable (or similar) + is at least once compared to a variable (or similar)
Here are some examples from actual Open Source code :
shop_get : written : $context['collection_operation_name'] = 'shop_get'read : $operationName !== 'shop_get'
- public
- written :
$access = 'PUBLIC'$this->access = 'PUBLIC'
- read :
$access != 'PUBLIC'$access == 'PUBLIC'$this->access == 'PUBLIC'$vars['object']->access != 'PUBLIC'
- written :
Some of those patterns should definitely be further investigated.
Inventories, inventories everywhere
Inventories use a different point of view on the code : they gather pieces of code with the same properties, and give the auditor a broad and wide view over their usage. With business knowledge and experience, it becomes easy to improve the consistency of a large code base, and bring it to a better state of harmony.
There are inventories of various kind : we have reviewed variable, exception, error messages and even string inventories. With each of them, we have applied different strategies : raw review, spelling, frequency, or advanced patterns like possible status and enumerations.
Inventories are a great tool to tame the infamous magic number problem : literals, that litters the code without any explanations. Inventories detect some of them, and give us a chance to refactor literals into something more readeable. They are not bugs, but rather maintenance helpers.
Happy auditing!