 There are two moments in the life cycle of a project where you can apply a long known best practice : « write test first, then the code ». The first one is when you start writing the code, and you have some time. The second is when the current architecture of the software has reached its maximal potential, and it is time to rewrite it, or at least, one of its main component. That’s when you are left alone in the dark, with a white page, and a bunch of Unit Tests : the only solution is to rewrite PHP code with unit tests.
There are two moments in the life cycle of a project where you can apply a long known best practice : « write test first, then the code ». The first one is when you start writing the code, and you have some time. The second is when the current architecture of the software has reached its maximal potential, and it is time to rewrite it, or at least, one of its main component. That’s when you are left alone in the dark, with a white page, and a bunch of Unit Tests : the only solution is to rewrite PHP code with unit tests.
This is my own story.
Rewrite PHP code from scratch is a bad idea
Rewriting from scratch is the worst idea in the tool chest : it means destroying all experience that was accumulated while building the previous version, and probably, doing the same mistakes again. And, while you’re doing at that, the rest of the world will no wait, but patiently pile up new challenges for your software. Don’t go down that road without utter craziness or good reasons.
And by good reasons, rebuilding the core is one of them. It has to be done after realizing that you can’t overcome the current code’s limitation with small patches : it has to be a major upgrade, one that will set aside several of the initial concepts. So, as a first step to a rewrite, you need to learn from the previous version what to avoid in the second version. That way, it is not a total rewrite, although you’ll start with a white page.
Tests are hard-coded experience
The other source of experience that is not lost is such an endeavor are the unit tests. All that was possible in the previous version will be available to the new version if the tests passes. So, keeping those old tests ready may serve as a guideline to build the new code. We’ll see that 100 % code coverage is desirable, but not necessary.
That’s what I had to do with the move from Gremlin 2.0 to Gremlin 3.0, for the exakat engine. Gremlin is an open source graph traversal language, that is plat-form agnostic. I started using it when it was a default part of Neo4j, around version 1.7, and kept following it until now. A few years later, Neo4j is now pushing its own Cypher language, making it more difficult to use Gremlin, and on top of that, Gremlin 2.0 reached its end of life.
The migration from Gremlin 2.0 to 3.0 was a lot more difficult than expected. Replacing about six hundred queries, one by one, proved to be difficult : apparently, I had used a lot of special tricks that were no more available. In particular, I had a heavy usage of closures and lambda functions, base on Groovy, a scripting language used within Gremlin. This is still part of Gremlin 3.0, but it is hidden, Gremlin is moving to a more abstract level of language : more declarative thank command-based.
After a few attempts at upgrading the first queries, and soon realizing that it was time for an internal engine rewrite, I decided to rewrite the core part of exakat. I knew exactly what to change (move more of the logic into PHP, reduce the import, make a one-pass PHP code analyzer) and I had the UT to keep me from making mistakes.
First day : 1786 tests, no code
The first day was dedicated to collecting the tests, and preparing the project for the new code. Of course, I checked my UT framework, and since there is no code, I got 1784 errors. Yes, that’s when I realized that 2 tests were passing, even though there is no actual code. So, I reviewed them: those were checking that some bad behavior was not happening, but it didn’t check that good behavior was enforced at the same time. Imagine that the test was ensuring no ‘Z’ appeared in the results, but didn’t check that the results were… non empty. The tests were still useful, but I upgraded them anyway.
Then, I decided to choose one of the UT and make this one my first target. That gave me a target for the new code, and a first dot on the UT reports. Obviously, I left the hard tests for later, and choose an easy one (Integer additions) : then I started coding. Having already though about the conception made it quite easy. Soon, I realized I also needed a way to call the new objects from the old UT, and had to write some adapter. And also, a way to read the new results from the new code, and make the old UT understand it too. After going out of my way for each of those detours, I got my first dot on the UT ! Although, it too three days !
Yes, three days. The actual core coding was quite quick, but all the ancillary tasks, like command-line parsing, logging, debugging, and adapting to the UT had also to be done at that first step. So, it looked like I was doing a lot of coding, just to check a very simple feature of the old code. 3 days was really long, and, in the end, stressful : will I really finish the job in 3 * 1785 days ?
Second Unit Test to pass
The second UT to pass was « addition with variables ». Now, this one took another half a day. Compared to the previous 3 days, that was quick, and it was also quite uneventful. I was now in getting used to the new code, I could refer to already-working code for help. I still had to build some missing features (early stage, right?) but I also had some of them working, so it went faster.
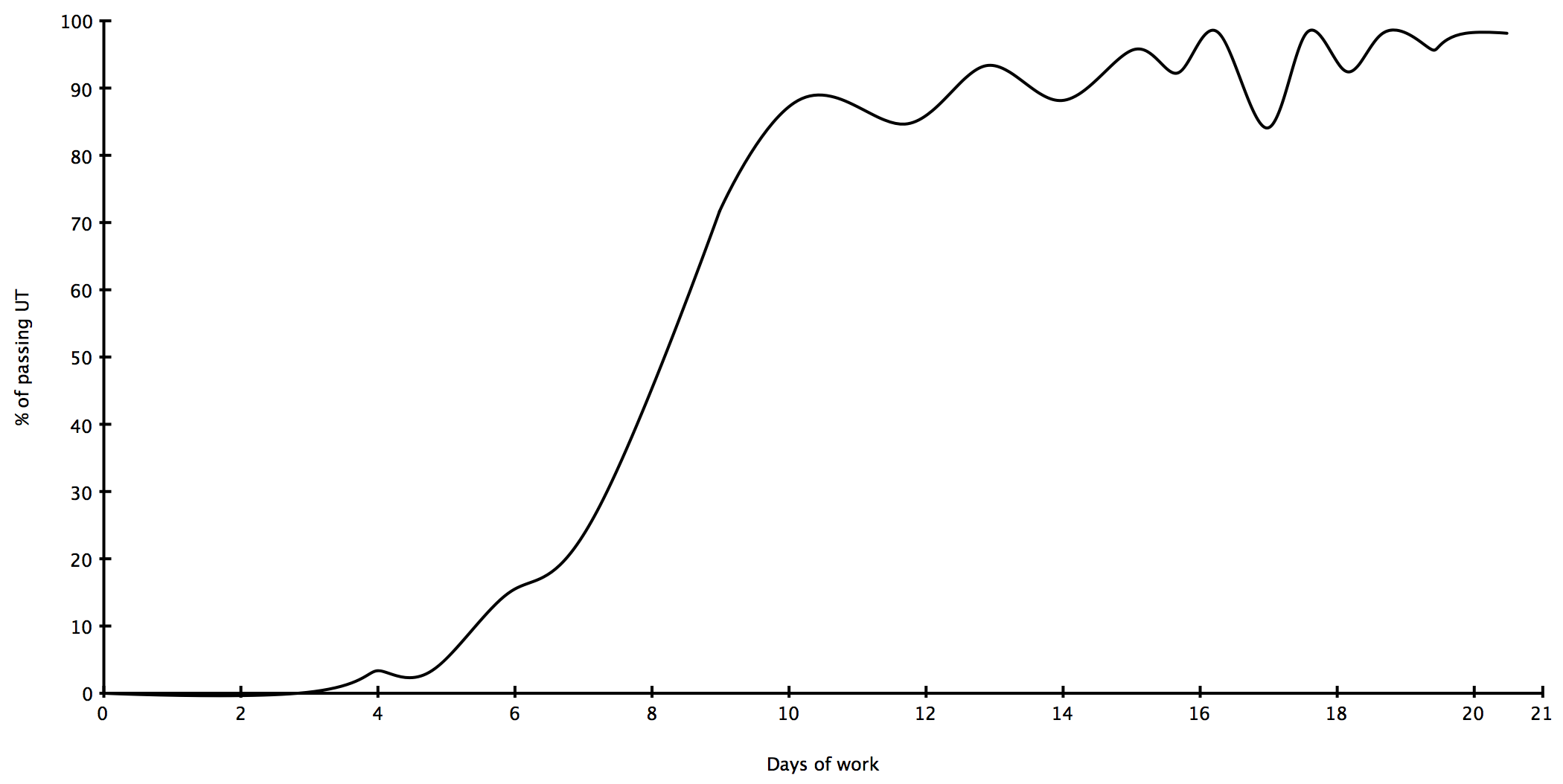
And so did the third, and the fourth. The next 30 UT went faster and faster, so I finished the first week with a good tempo and some restored enthusiasm. Besides that, the new code was giving some great signs of speed and robustness that was great to feel, though UT wouldn’t show at all. Actually, 2 % of UT in a week was not the expected results.
The quick and satisfying phase
The second week started off strong, and the old UT moved from F to dot quite quickly and steadily, until I reached the level of 1400 UT. Compared to the 30 UT of the first week, that was a lot better. The progression was not smooth : sometimes, adding a new feature would make 100 UT work at the same time, and then, tweaking the same feature for 2 hours would only make 2 extra UT pass : there was no real feeling of controlled progression. Obviously, some of the tests where redundant, some were mere variations one of another. Also, some of the tests were made to ensure edge cases of the previous implementation were OK, and they just weren’t needed anymore with the new implementation. That was cool.
Of course, on the other side, if edges cases of version 1 passed quickly, it also meant that edge cases of version 2 were different, new and somewhere else but not known yet. That was the main pain during the third week. The third week saw a reduced increase in the new test passing, and the appearance of regressions. Actually, that is probably another reason for the previous phase to be quick : each feature was prepared independently from the others. They were also tested independently (for example, testing addition without multiplication). When the independent tests ran out, I started running tests that handled two (or more) features at the same time. And, once I found how the two features would settle precedence, then it usually meant that other part of the code was in ruin. Regression is a mean player.
Here comes regression
So, during the third week, the evolution of passing UT kept going up and down. The general trend was still to go up, toward 100 %, but there was also peaks and valleys. The peaks tended to be smaller and smaller, and the valleys less and less deep. They also grew further and further away from each other, so each new regression was making less of an impact on the rest of the code.
Finally 100 % UT
By the end of the third week, the new code was passing all the old UT. The new code had kept its potential and speed improvement, so the whole rewrite was well worth it. Sadly, the second part of the software was not so happy to work with the new first part : some of its own UT now failed.
So several conclusions had to be made :
- When rebuilding a core part, there is a need to make more UT, since a part of the old ones are now deprecated, and new issues and edge cases will appear. I think I won’t drop the old tests, but create new ones, probably around 10 – 15 % more.
- There are ‘leaks’ between the two internal part of the software, meaning that some results of the first part are actually tested in the second part. The UT in the first phase mainly checked that all is running fine, and nothing blocks the analysis. But the actual testing of value is done by the second phase. That means another 1400 UT to check.
- UT did a good job at shepherding the new version : it was good to have target to focus on, both as micro-target (let’s make this test pass) and global target (let’s make all tests pass) and to have a scale of progression (80 % UT passes, yeah!). On the other hand, UT didn’t help when it comes to organize work schedule.
- UT were NOT sufficient as a target : some tests are just wrong, some tests were missing (100 % coverage, anyone?), some were good for the old version but useless for the new one. In the end, it was really good to have them. And more important, some new tests are now needed as the new implementation fails where the old one didn’t and vice-versa.
Don’t forget the manual tests
As a final note, here is a trick I used during this time : all manual tests were recorded. As a part of the initial phase, I realized that I was about to do a lot of manual testing : I start from the UT, but, just to be sure, I do also mutate the input to check if some edge case are also covered. Those manual test are very important for dev, and should be kept for later reuse. So, as an extra layer of the UT framework, I added a logger that kept track of all manual test. I’ve collected another 2820 tests this way : even if many of them are already made into UT, that will be a treasure chest to add new UT.